TOKN: Token-Optimised KiCad Notation
Token-Optimised KiCad Notation - 92% token reduction format for LLM circuit generation, with benchmark suite and model comparison
![]()
Teaching LLMs to generate electronic circuits
Why I Built This
I wanted to see if LLMs could design circuits. Not just talk about circuits — actually output something you could fabricate.
The problem: KiCad schematic files are absurdly verbose. A simple voltage regulator circuit might be 50KB and 25,000 tokens. That’s expensive for training, impractical for generation, and most of those tokens are just formatting noise — UUIDs, coordinates, metadata. The actual electrical information is maybe 5% of the file.
So I built TOKN — a compact format that strips out the noise while keeping everything that matters electrically. Components, pin mappings, nets, wires. 92% fewer tokens, fully reversible back to KiCad.
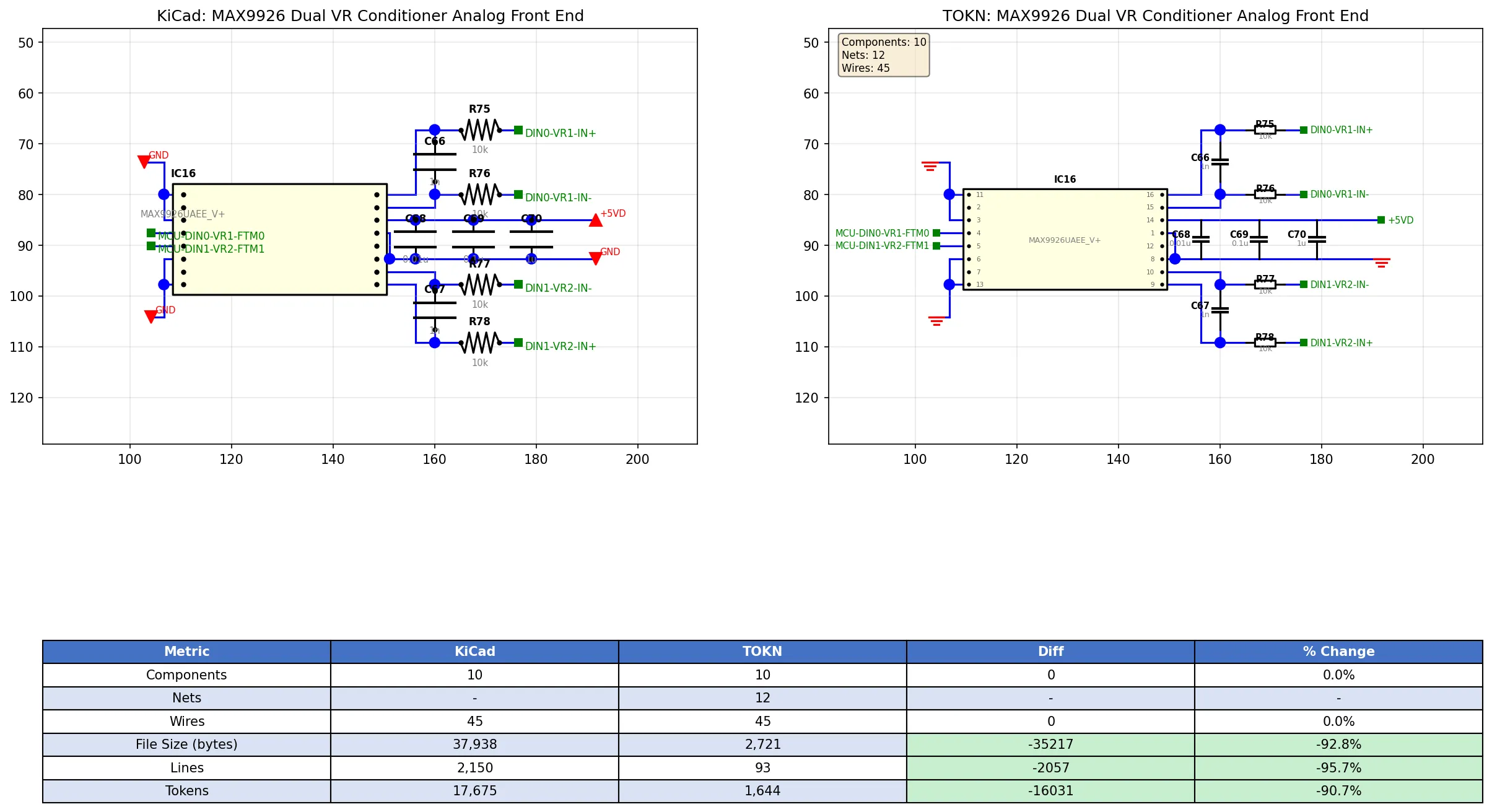 Round-trip: Original schematic (left) vs reconstructed from TOKN (right)
Round-trip: Original schematic (left) vs reconstructed from TOKN (right)
The Interesting Discovery
Once I had the format, I built a benchmark suite and tested a bunch of models. The results were surprising.
Syntax is easy. Knowledge is hard.
Llama 3.1 8B achieved 80% syntax validity — it learned how to write TOKN just fine. But it scored 6/100 on electrical correctness. The outputs looked right but were nonsense. Pin 3 connected to pin 7 for no reason. Power rails going nowhere. Components with impossible configurations.
The model knew the format but not electronics.
Larger models did better because they’d absorbed actual circuit knowledge during pre-training. Claude Opus 4.5 hit 58.9/100 — the first model to break 50% on correctness. It actually knows that op-amps need feedback resistors and that VCC goes to the power pin, not because I taught it, but because it learned that somewhere in its training.
| Model | AI Score | What It Tells You |
|---|---|---|
| Claude Opus 4.5 | 58.9/100 | Knows electronics |
| Qwen 3 235B | 49.6/100 | Best open-source option |
| Llama 3.1 8B | 12.6/100 | Knows format, not circuits |
Why Fine-Tuning Won’t Help
Between CircuitSnips and scraping GitHub, I have around 4,300 KiCad schematics. The obvious move is fine-tuning, right?
I ran the numbers. Fine-tuning teaches format, not facts. A fine-tuned Llama 8B would produce perfect TOKN syntax with the same garbage pin assignments. The knowledge ceiling is set during pre-training — you can’t teach a model what a TL072 is by showing it more schematics.
Realistically, a fine-tuned 8B might reach 28/100. Qwen 235B hits 49.6/100 out of the box. The economics don’t work.
The better path is probably RAG — feed the model IC datasheets at inference time. Give it the pinout for the specific chip it’s trying to use. That’s domain knowledge injection, not format training.
What Actually Works
The project ended up being more about understanding LLM limitations than building a production tool.
What works:
- Token compression (92% reduction, fully reversible)
- Format learning (top models hit 100% syntax validity)
- Relative model ranking (benchmark results are consistent)
What doesn’t:
- Small models generating correct circuits
- Fine-tuning to overcome knowledge gaps
- Expecting electrical correctness without domain knowledge
The format itself is solid. The benchmark is useful for comparing models. But the dream of “prompt → working circuit” needs more than just a compact notation. It needs models that actually understand electronics, or hybrid systems that inject that knowledge at runtime.
The Format
For the curious, TOKN looks like this:
@C R1 res 10k R_0603 (25.4,50.8) s2.54 r0
@C U1 MAX9926 MAX9926UAEE SOIC-16 (76.2,63.5) s2.54 r0
@P U1 1:IN+ 2:IN- 3:VDD 4:OUT 5:GND
@N VCC: U1.3 C1.1 R1.2
@N GND: U1.5 C1.2 C2.2
@W (25.4,50.8)-(25.4,63.5)-(50.8,63.5)Components, IC pin definitions, nets, wires. Everything you need to reconstruct the schematic, nothing you don’t.
The full spec and benchmark suite are in the repo if you want to dig deeper.
Source Code: GitHub